作者:王駿瑋 David Ishayahu
碳排放看不見。企業治理的真相埋在兩百頁報告書裡。一個社區計畫到底幫了多少人,沒人量過。你的身體每天都在變化,但你只會在痛的時候才注意到。
這四件事有一個共同點:它們都是看不見的系統。
數據科學做的事,就是讓這些系統被看見。同一套方法論,拆成統計學、程式設計、領域知識三根柱子,架在不同的觀測對象上。環境、企業、社會、人體,四個維度,同一個底層邏輯。
碳排放量不是讀電表就有的數字。一家企業的碳足跡涉及能源消耗、物流運輸、員工通勤、甚至供應鏈上游的製造過程。這些資料散落在不同系統、不同格式、不同單位裡。
數據科學在這裡做的事:把這些碎片拼起來。從政府開放資料抓排放係數,從企業財報抓營運數據,用統計模型估算無法直接量測的排放源。然後交叉驗證,確保算出來的數字經得起第三方查核。
台灣上市櫃公司每年要交永續報告書。問題是:一份報告動輒兩百頁,堆滿圖表和專有名詞。投資人沒時間讀,主管機關看不完,企業自己也不確定寫的內容是否符合最新法規。
數據科學怎麼解這個問題?讓電腦學會「讀中文」。這套技術叫自然語言處理(NLP),簡單說就是教電腦把一段文字拆開、理解意思、跟標準比對。比如報告書裡寫「本公司已設定減碳目標」,電腦能判斷這句話有沒有回答 IFRS S2 第 29 條的要求。不是取代人類判斷,是讓人類把注意力放在真正重要的地方。
一個社區發展計畫投入了三年時間、幾百萬預算。成果呢?「幫助了很多人」「改善了社區環境」。這些話聽起來不錯,但經不起追問:多少人?改善了什麼?跟沒做這個計畫比,差在哪?
數據科學提供了量化影響力的框架。建立基線(介入前的狀態),設定指標(收入、就業、教育程度),收集數據(問卷、行政資料、感測器),然後用統計方法分離「計畫帶來的改變」和「本來就會發生的趨勢」。讓影響力從感覺變成證據。
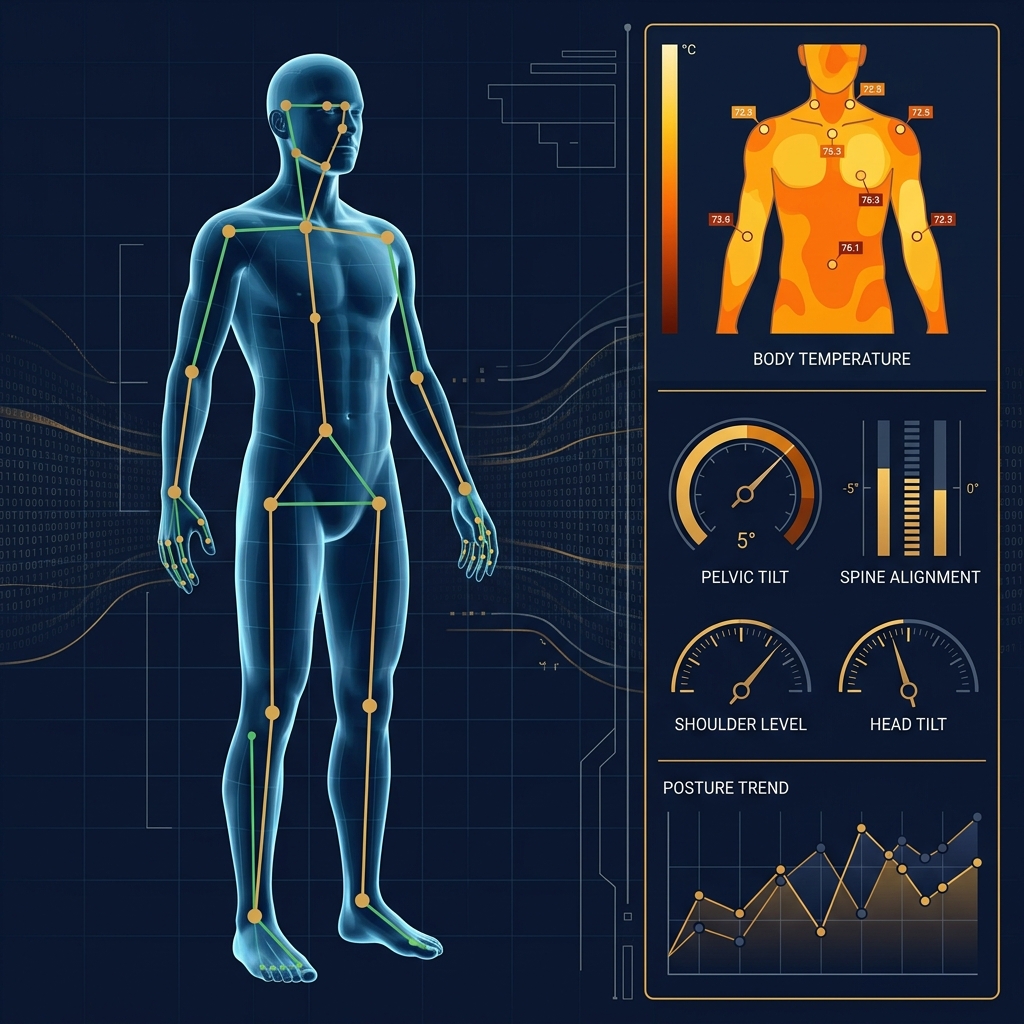
你知道自己的體脂率,但你知道自己的肩膀左右高低差幾度嗎?你知道每天走幾步,但你知道自己的身體在一次運動前後發生了什麼具體變化嗎?
數據科學在人體領域做的事,是把「感覺」變成「數據」。用姿勢偵測技術量化身體的傾斜與不對稱,用溫度感測記錄體表熱分佈的變化,用統計模型追蹤這些指標隨時間的趨勢。不做診斷,只做記錄和觀察。讓身體的變化被看見、被理解、被追蹤。
這四個維度不是四個無關的業務。它們共用同一套數據科學方法論:收集原始資料、清洗整合、統計建模、交叉驗證、產出可操作的結論。差別只在觀測的對象不同。
收集
從散落的來源取得原始數據
整合
不同格式、單位、系統的資料拼在一起
建模
用統計和機器學習找出模式
驗證
交叉比對,確保結論經得起檢驗
這頁講的是數據科學「用在哪裡」。如果你對數據科學「是什麼」更感興趣,可以看方法論的完整說明。
本內容僅供參考,不構成專業建議。涉及碳排放計算的數據應依據專業碳盤查機構之查證結果。涉及健康數據的內容不構成醫療診斷或治療建議,如有健康疑慮,請諮詢醫師。影響力評估結果受方法論與數據來源影響。